
从Zeppelin 0.9开始将正式支持Flink 1.10。Flink是一个批流统一的计算引擎,本文将从第一个wordcount的例子为起点来讲述如何在Zeppelin中使用Flink。
准备工作
在Zeppelin中适用Flink,需要下载最新的Zeppelin 0.9.0 以及 Flink 1.10 ,除了下载Flink的标准release,如果你要使用Flink on Yarn模式或者连接Hive,那么你还需要下载其他Flink组件。
Flink on Yarn 需要的组件:
- flink-hadoop-compatibility (https://repo1.maven.org/maven2/org/apache/flink/flink-hadoop-compatibility_2.11/1.9.1/flink-hadoop-compatibility_2.11-1.9.1.jar)
- flink-shaded-hadoop-2-uber (https://repo.maven.apache.org/maven2/org/apache/flink/flink-shaded-hadoop-2-uber/2.7.5-7.0/flink-shaded-hadoop-2-uber-2.7.5-7.0.jar)
连接Hive需要的组件:
- flink-connector-hive
- hive-exec
使用pyflink需要的组件
- flink-python
这是我的lib目录下的所有jar (也可以参考Flink官方文档,https://ci.apache.org/projects/flink/flink-docs-master/dev/table/hive/scala_shell_hive.html)
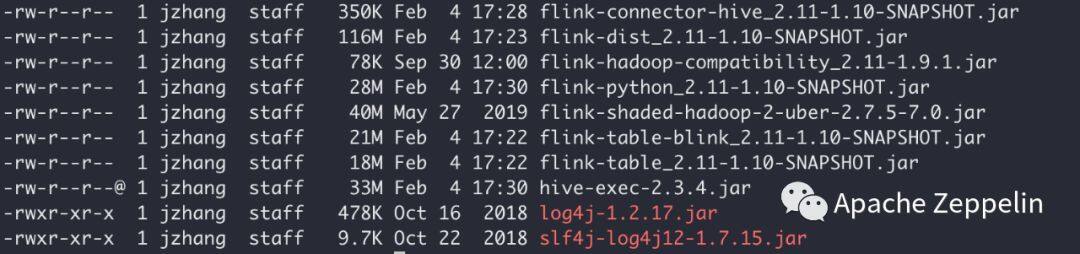
配置Zeppelin + Flink
接下来是配置Zeppelin和Flink。首先解压缩Zeppelin包之后,cd到Zeppelin目录运行下面运行这个命令启动Zeppelin
bin/zeppelin-daemon.sh start
然后在浏览器里打开http://localhost:8080 就可以看到 Zeppelin页面了。
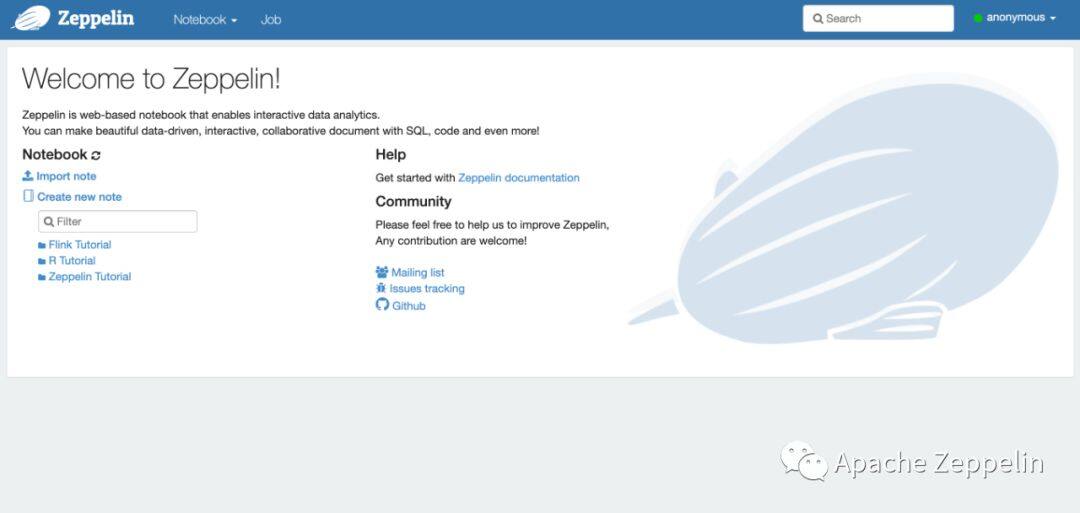
就下来就需要配置Flink Interpreter。在Zeppelin中可以使用3种不同的Flink集群模式
- Local
- Remote
- Yarn
下面将分别说明如何配置Flink Interpreter来运行这3种模式。
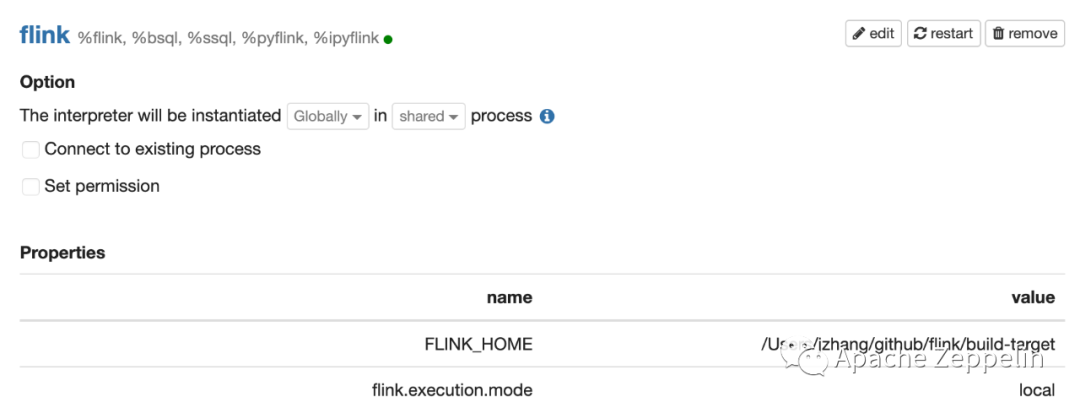
Local 模式
Flink的Local模式会在本地创建一个MiniCluster,适合做POC或者小数据量的试验。必须配置FLINK_HOME 和 flink.execution.mode
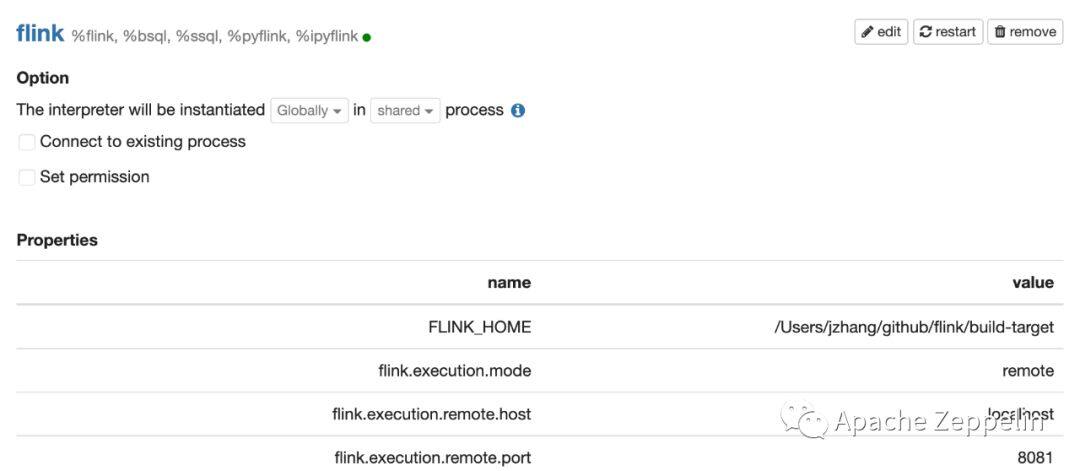
Remote 模式
Flink的Remote模式会连接一个已经创建好的Flink集群,一般是Flink standalone集群。除了配置FLINK_HOME 和 flink.execution.mode外,还需要配置flink.execution.remote.host和flink.execution.remote.port来指定JobManager的地址。
YARN 模式
Flink的Yarn模式会在Yarn集群中创建Flink Cluster。除了配置FLINK_HOME 和 flink.execution.mode还需要配置HADOOP_CONF_DIR,并且要确保Zeppelin这台机器可以访问你的hadoop集群。
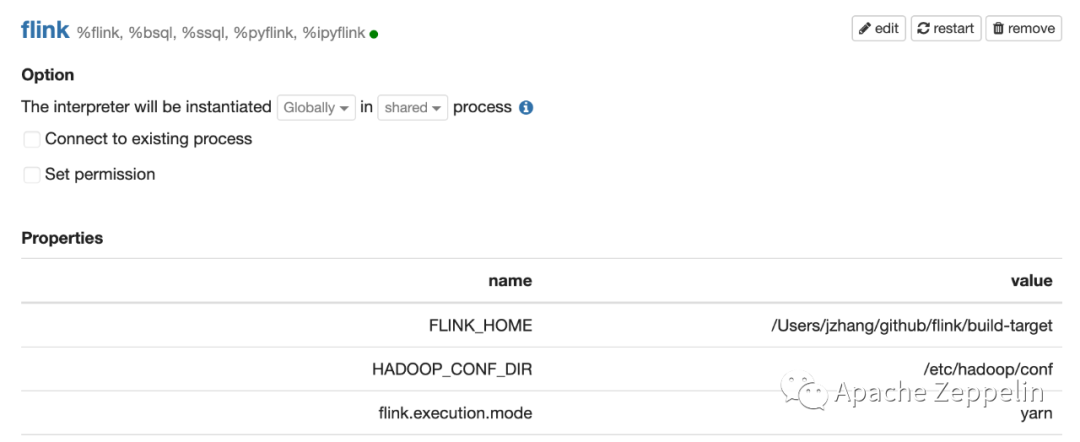
验证Flink Interpreter
完成了上面的配置之后,可以运行下面的wordcount代码来验证Flink Interpreter是否能正常工作。
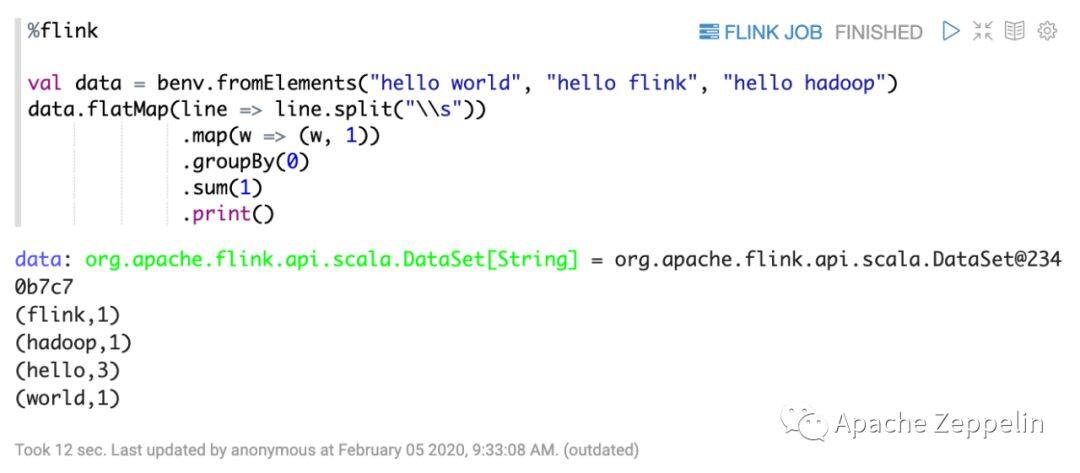
如上图所示,你可以看到WordCount的输出,以及右上角的Flink JOB链接,点击这个链接你可以看到Flink Web UI中关于这个WordCount Job的详细信息。
这就是如何在Zeppelin运行Flink WordCount的过程,如果有碰到任何问题,请加入下面这个钉钉群讨论。后续我们会有更多Tutorial的文章,敬请期待。