本文讲述如何使用Flink SQL + UDF来做Batch ETL和BI数据分析的任务。

首先介绍下Zeppelin中的Flink Interpreter类型。Zeppelin的Flink Interpreter支持Flink的所有API (DataSet, DataStream, Table API )。语言方面支持Scala,Python,SQL。下图是Zeppelin中支持的不同场景下的Flink Interpreter。
| Name | Class | Description |
| %flink | FlinkInterpreter | Creates ExecutionEnvironment/StreamExecutionEnvironment/BatchTableEnvironment/StreamTableEnvironment and provides a Scala environment |
| %flink.pyflink | PyFlinkInterpreter | Provides a python environment |
| %flink.ipyflink | IPyFlinkInterpreter | Provides an ipython environment |
| %flink.ssql | FlinkStreamSqlInterpreter | Provides a stream sql environment |
| %flink.bsql | FlinkBatchSqlInterpreter | Provides a batch sql environment |
下图例举了所有重要的Flink配置信息,除此之外你还可以配置任意Flink的Configuration(https://ci.apache.org/projects/flink/flink-docs-master/ops/config.html)
| Property | Default | Description |
| FLINK_HOME | Flink的安装目录 | |
| HADOOP_CONF_DIR | Hadoop配置信息目录 | |
| HIVE_CONF_DIR | Hive配置信息目录 | |
| flink.execution.mode | local | Execution mode of flink, e.g. local | yarn | remote |
| flink.execution.remote.host | jobmanager hostname if it is remote mode | |
| flink.execution.remote.port | jobmanager port if it is remote mode | |
| flink.jm.memory | 1024 | Total number of memory(mb) of JobManager |
| flink.tm.memory | 1024 | Total number of memory(mb) of TaskManager |
| flink.yarn.appName | Zeppelin Flink Session | Yarn app name |
| flink.yarn.queue | queue name of yarn app | |
| flink.execution.jars | additional user jars (comma separated) | |
| flink.execution.packages | additional user packages (comma separated), e.g. org.apache.flink:flink-connector-kafka_2.11:1.10,org.apache.flink:flink-connector-kafka-base_2.11:1.10,org.apache.flink:flink-json:1.10 | |
| zeppelin.pyflink.python | python | python binary executable for PyFlink |
| table.exec.resource.default-parallelism | 1 | Default parallelism for flink sql job |
| zeppelin.flink.scala.color | true | whether display scala shell output in colorful format |
| zeppelin.flink.enableHive | false | whether enable hive |
| zeppelin.flink.printREPLOutput | true | Print REPL output |
| zeppelin.flink.maxResult | 1 | max number of rows returned by sql interpreter |
StreamExecutionEnvironment, ExecutionEnvironment, StreamTableEnvironment, BatchTableEnvironment
Flink Interpreter (%flink) 为用户自动创建了下面6个变量作为Flink Scala程序的入口。
senv(StreamExecutionEnvironment),benv(ExecutionEnvironment)stenv(StreamTableEnvironment for blink planner)btenv(BatchTableEnvironment for blink planner)stenv_2(StreamTableEnvironment for flink planner)btenv_2(BatchTableEnvironment for flink planner)
PyFlinkInterpreter (%flink.pyflink, %flink.ipyflink) 为用户自动创建了6个python变量作为PyFlink程序的入口
- s_env (StreamExecutionEnvironment),
- b_env (ExecutionEnvironment)
st_env(StreamTableEnvironment for blink planner)bt_env(BatchTableEnvironment for blink planner)st_env_2(StreamTableEnvironment for flink planner)bt_env_2(BatchTableEnvironment for flink planner)
Flink 1.10中有2种table api的planner:flink & blink.
- 如果你用DataSet api以及需要把DataSet转换成Table,那么就需要使用Flink planner的TableEnvironment (
btenv_2andstenv_2). - 其他场景下, 我们都会建议用户使用
blinkplanner. 这也是Flink sql使用的planner(%flink.bsql&%flink.ssql)
%flink.bsql 是用来执行Flink的batch sql. 运行 help 命令可以得到所有可用的命令

总的来说,Flink Batch SQL可以用来做2大任务:
- 使用
insert into语句来做 Batch ETL - 使用
select语句来做BI 数据分析
下面我们基于Bank (https://archive.ics.uci.edu/ml/datasets/bank+marketing)数据来做Batch ETL任务。首先用Flink Sql创建一个raw 数据的source table,以及清洗干净后的sink table。

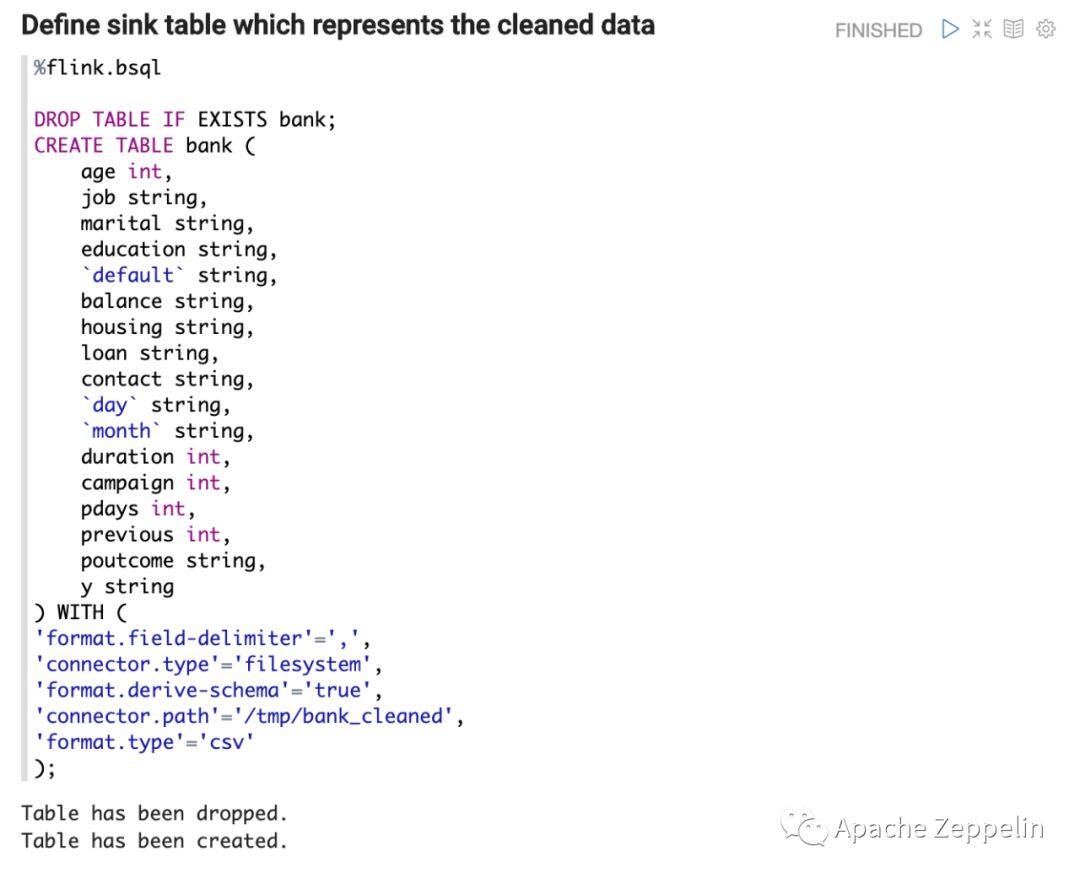
然后再定义Table Function来parse raw data。

接下来就可以用insert into语句来进行数据转换(source table –> sink table)

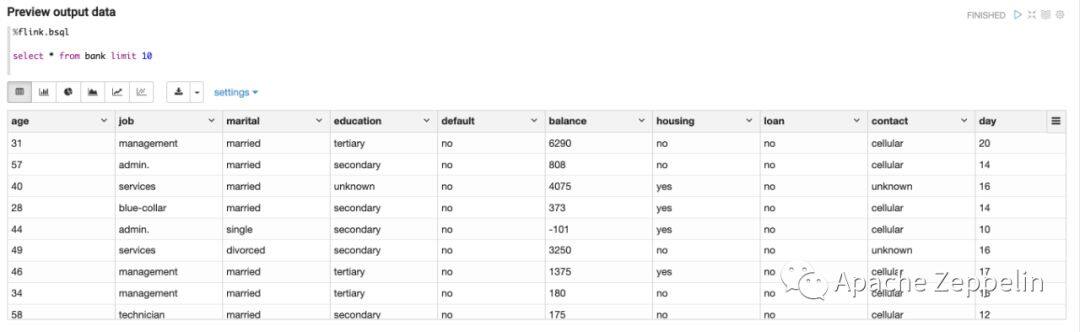
用select语句来Preview最终数据,验证insert into语句的正确性
经过上面的数据清洗工作,接下来就可以对数据进行分析了。用户不仅可以使用标准的SQL Select语句进行分析,也可以使用Zeppelin的dynamic forms来增加交互性(TextBox,Select,Checkbox)

使用Flink UDF
SQL虽然强大,但表达能力毕竟有限。有时候就要借助于UDF来表达更复杂的逻辑。Flink Interpreter 支持2种UDF (Scala + Python)。下面是2个简单的例子。
Scala UDF
%flink
class ScalaUpper extends ScalarFunction {
def eval(str: String) = str.toUpperCase
}
btenv.registerFunction("scala_upper", new ScalaUpper())
Python UDF
%flink.pyflink
class PythonUpper(ScalarFunction):
def eval(self, s):
return s.upper()
bt_env.register_function("python_upper", udf(PythonUpper(), DataTypes.STRING(), DataTypes.STRING()))
创建完UDF之后,你就可以在SQL里使用了。
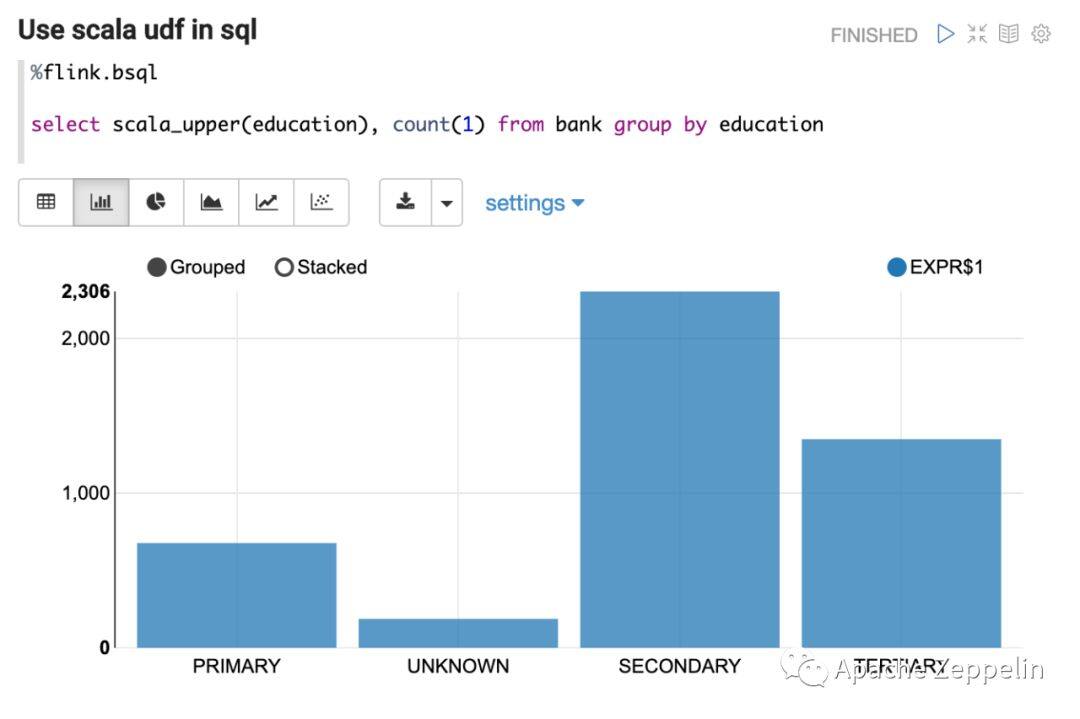

对Hive数据的数据分析
除了可以分析Flink SQL创建的table之外,Flink也可以分析Hive上已有的table。如果要让Flink Interpreter使用Hive,那么需要做以下配置
- 设置
zeppelin.flink.enableHive为true - Copy 下面这些 dependencies 到flink的 lib 目录
- flink-connector-hive_{scala_version}-{flink.version}.jar
- flink-hadoop-compatibility_{scala_version}-{flink.version}.jar
- flink-shaded-hadoop-2-uber-{hadoop.version}-{flink-shaded.version}.jar
- hive-exec-2.x.jar (for Hive 1.x, you need to copy hive-exec-1.x.jar, hive-metastore-1.x.jar, libfb303-0.9.2.jar and libthrift-0.9.2.jar)
- 在Flink interpreter setting 里或者 zeppelin-env.sh里指定
HIVE_CONF_DIR - 在Flink interpreter setting 指定 zeppelin.flink.hive.version 为你使用的Hive版本
下面就用一个简单的例子展示如何在Zeppelin中用Flink查询Hive table
1. 用Zeppelin的jdbc interpreter查询hive tables

2. 用Flink sql 查询 hive table的schema
3. 用Flink Sql 查询hive table